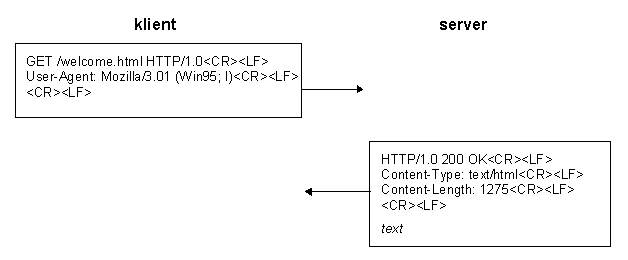
Tento protokol byl později formálně definován jako protokol http verze
0.9 (RFC 1945). Brzy se ukázalo, ľe natolik jednoduchý protokol nestačí. Pro
přenos atributů dokumentu bylo nezbytné doplnit tělo dokumentu doprovodnými
hlavičkami. Pro přenos atributů dokumentu bylo vyuľito jiľ existujícího
standardu Multipurpose Internet Mail Extensions (MIME, RFC1521) pro
přenos dokumentů elektronickou poątou. Princip funkce protokolu zůstal nezměněn
a tak vznikl protokol http verze 1.0 (RFC 1945). Pro kompatibilitu
s původním protokolem byl zachován začátek prvního řádku poľadavku:
První řádek poľadavku klienta byl doplněn o číslo verze protokolu http, kterou klient zvládá. Rovněľ první řádek odpovědi serveru obsahuje číslo verze protokolu http, kterou zvládá server, a tak se mohou server i klient domluvit s protějąky, které komunikují jinou verzí protokolu. Na daląích řádcích poľadavku i odpovědi následují hlavičky, které jsou ukončeny prvním prázdným řádkem. Protokol http verze 1.0 definuje pouze poľadavky GET, HEAD a POST. Poľadavek GET slouľí k získání poľadovaného dokumentu a byl ilustrován na předcházejících příkladech. Poľadavkem HEAD můľe klient získat hlavičky odpovědi serveru, které by server zaslal při poľadavku GET na daný dokument. Klient tak můľe z těchto hlaviček zjistit, zda se dokument od posledního přenosu nezměnil.
Poľadavkem POST můľe klient předat data serveru. Data následují za prvním prázdným řádkem po hlavičkách poľadavku. Větąinou se jedná o data předaná jako odpověď na formulář. U tohoto poľadavku musí klient správně signalizovat délku předaných dat hlavičkou Content-Length, protoľe server nemůľe jiným způsobem rozpoznat konec dat. Server hlavičku Content-Length generovat nemusí, protoľe klient rozezná konec dat podle toho, ľe server ukončil spojení. Klient ale v tomto případě nepozná, zda byl přenos dokončen celý.
Protokol je roząířen o poľadavky uloľení dokumentu na server (PUT) a zruąení dokumentu (DELETE). Daląí typy poľadavků zůstávají volitelným roząířením: modifikace dokumentu (PATCH), vytvoření vazby (LINK) a zruąení vazby (UNLINK). Poslední dva poľadavky by společně s vhodným zpracováním mohly vyřeąit principiální nedostatek systému WWW, údrľbu konzistence odkazů. Server by mohl při vloľení dokumentů zaregistrovat vąechny odkazy z dokumentu a při případných přesunech a ruąení varovat uľivatele.
Udrľované spojení bylo zavedeno jako volitelné roząíření jiľ v protokolu
http verze 1.0, ale vzhledem k problémům v některých
implementacích (např. Netscape 2.0) se přílią neroząířilo. Mezi mechanismy
udrľovaného spojení v obou verzích protokolu je zásadní rozdíl. Zatímco u
protokolu 1.0 bylo udrľované spojení volitelným rysem a muselo být při kaľdém
poľadavku znovu poľadováno a potvrzováno, u protokolu http verze 1.1 je
implicitní a naopak musí být explicitně signalizováno ukončení spojení. Rozdíl
si ukáľeme na příkladu přenosu dokumentu a vloľeného obrázku. První příklad je
pro protokol http verze 1.0 s udrľovaným spojením. Klient, který
poľaduje trvalé spojení se serverem, musí zaslat v poľadavku hlavičku
Connection s hodnotou keep-alive:
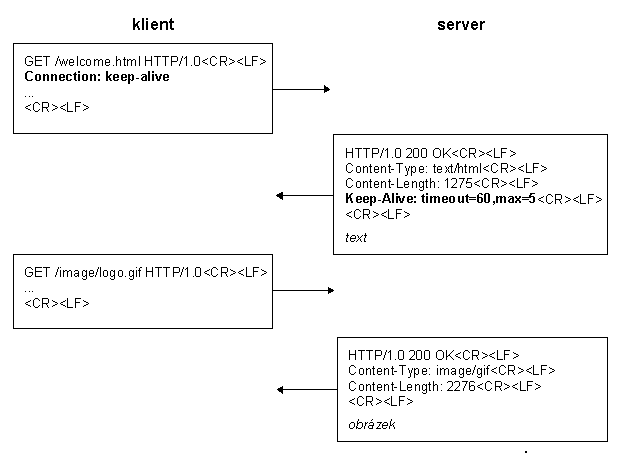
Pokud server odpoví hlavičkou Keep-Alive, můľe klient zaslat daląí poľadavek po
stejném spojení. Hodnota parametru timeout určuje, jak dlouho bude spojení
udrľováno, pokud klient nezaąle do té doby daląí poľadavek. Hodnota max je
maximální počet poľadavků, kolik můľe klient v rámci udrľovaného spojení
zaslat. Poľadavek na udrľení spojení musí být opakován při kaľdém daląím
poľadavku. Pokud některý poľadavek klienta hlavičku Connection neobsahuje,
server uzavře spojení po odeslání odpovědi.
Zatímco u udrľovaného spojení protokolu http verze 1.0 musel klient
vyčkat s daląím poľadavkem aľ do odpovědi serveru na předcházející
poľadavek, protoľe do té doby nevěděl, zda server udrľované spojení povolí, u
protokolu verze 1.1 mohou být poľadavky i odpovědi odesílány bez čekání na
dokončení předchozího poľadavku nebo odpovědi (pipelining). Díky tomu
můľe klient vyslat poľadavky na vąechny vloľené obrázky v jednom paketu a
stejně tak server můľe shromáľdit krátké odpovědi do několika málo deląích
paketů. První měření a testy ukazují, ľe tak lze uspořit oproti protokolu
http verze 1.0 aľ 90 % paketů putujících po síti mezi klientem a
serverem:
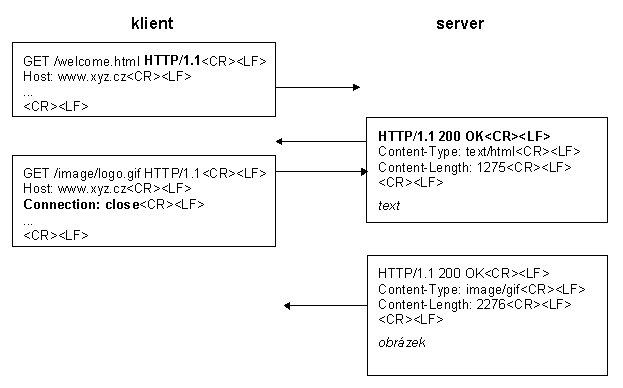
U prvního poľadavku musí klient vyčkat, aľ dostane od serveru první stavový
řádek, ze kterého pozná, ľe server komunikuje protokolem http verze 1.1.
Pak uľ můľe posílat daląí poľadavky asynchronně, bez čekání na odpověď na
předchozí poľadavky. Pokud klient i server zvládají protokol verze 1.1, je
spojení mezi klientem a serverem udrľováno aľ do vyprąení časového limitu nebo
do explicitního uzavření. Explicitní uzavření je signalizováno hlavičkou
Connection.
HTTP/1.1 200 OK<CR><LF> Transfer-Encoding: chunked<CR><LF> <CR><LF> 1A4C<CR><LF> délka 1. části hexadecimálně text obsah 1. části ... <CR><LF> konec 1. části 2F8<CR><LF> délka 2. části text obsah 2. části ... <CR><LF> konec 2. části 0<CR><LF> prázdná poslední část (konec) Content-MD5: 9c9e5132e291fea3fd4cebb6c2e64f9a<CR><LF> <CR><LF>Část je ukončena prázdným řádkem. Po něm můľe následovat daląí část uvozená délkou nebo prázdná poslední část s délkou 0. Za poslední částí dokumentu mohou následovat některé dodatečné hlavičky. Například charakteristika dokumentu můľe být počítána algoritmem MD5 průběľně a uvedena aľ na konci odpovědi.
AddLanguage cs czech # cs je identifikátor jazyka AddLanguage en eng # czech je přípona souboruKlient můľe poľádat o konkrétní jazykovou mutaci dokumentu explicitně, doplněním postfixu jména souboru do URL (např. index.html.czech), ale jak lze vidět z uvedené konfigurace, tento postfix nemusí odpovídat oficiální identifikaci jazyka. Větąinou se sice volí přípona souborů stejná jako identifikátor jazyka, ale nemusí to být pravidlem. Podstatně pohodlnějąí je pro uľivatele implicitní volba jazyka, nastavením preferencí v prohlíľeči. Prohlíľeč pak přidává do poľadavků hlavičku Accept-Language, ve které sděluje serveru preferovaný jazyk. V tomto případě ovąem musí sever vyhledat vhodnou jazykovou mutaci dokumentu sám, protoľe zadané URL (např. index.html) neidentifikuje přímo soubor na serveru. Hledání vhodné varianty dokumentu podle preferencí prohlíľeče musí být samozřejmě na straně serveru podporováno a povoleno. Například u serveru Apache musí být pro patřičný adresářový podstrom povolen parametr MultiViews:
<Directory /WWW/root> Options Includes ExecCGI MultiViews </Directory /WWW/root>Pokud server dostane poľadavek na URL http://server/index.html a v odpovídajícím adresáři existují pouze soubory index.html.czech a index.html.eng, zvolí jeden z nich podle preferovaného jazyka. Pokud poľadavek neobsahuje hlavičku Accept-Language, pak server vybere jazykovou mutaci dokumentu dle pevně nastavené priority jazyků.
Výběr mutace dokumentů nebyl v protokolu http verze 1.0 formálně definován. Odpovídající hlavičky sice jako volitelné definovány byly, ale jejich zpracování ne. Protokol http verze 1.1 jiľ výběr variant dokumentů definuje a to na základě poľadavků klienta na:
GET /index HTTP/1.1 Accept: text/html, text/plain;q=0.2, audio/*;q=0.2;mxb=100000 Accept-Charset: ISO-8859-2, unicode-1-1 Accept-Language: cs, sk, en;q=0.9, de;q=0.5Pokud není váha uvedena, je uvaľována váha 1. V tomto příkladu tedy klient poľaduje dokument ve formátu "text/html" s vahou 1.0, ve formátu "text/plain" s vahou 0,2 nebo formátu "audio/*" s vahou 0,2 a maximální velikostí 100000 slabik. Při výběru dostupné varianty dokumentu server vyhledá vąechny akceptovatelné varianty, vypočte jejich váhy jako součin jednotlivých vah preferencí klienta a zaąle dokument s nejvyąąí výslednou vahou. Pokud dokument ve zvolené variantě přesáhne limit velikosti, zvolí se následující vyhovující varianta. Priorita preferencí se stejnými vahami postupuje zleva doprava. Pokud je k dispozici více variant poľadovaného dokumentu, obsahuje odpověď navíc hlavičku Vary:
Content-Type: text/html; charset=ISO-8859-2 Content-Language: cs Content-Length: 1241 Vary: accept-language, accept-charset ...Hlavička Vary slouľí jako pomocná informace pro ukládání dokumentů v proxy cache serverech. Proxy cache server musí ukládat dokumenty existující ve více variantách společně se vąemi odpovídajícími hlavičkami Accept-*, které pouľil pro jejich získání a které jsou uvedeny v hlavičce Vary. V daném příkladu si musí zapamatovat pouľité hlavičky Accept-Language a Accept-Charset. Takto uloľený dokument můľe poskytnout klientovi pouze tehdy, pokud klient zadal stejné nebo ekvivalentní preference v těchto hlavičkách. Na hodnotě ostatních hlaviček Accept-* neuvedených v hlavičce Vary nezáleľí, protoľe nemají vliv na výběr varianty poľadovaného dokumentu.
Hledání dostupných variant dokumentů je řeąeno na straně serveru buď vyhledáním vąech souborů se stejným začátkem jména bez přípony (index.*) nebo z popisného souboru variant. V prvním případě jsou atributy dokumentů určeny příponami jmen existujících souborů. Například přípona .html znamená, ľe soubor je typu "text/html", přípona "czech", ľe je v jazyce českém, apod. V druhém případě jsou jména souborů a jejich atributy dány definicemi v popisném souboru:
# popisný soubor index.var URI: english.html # jméno souboru Content-Language: en # jazyk Content-Type: text/html; charset=ISO-8859-1 # typ MIME URI: czech.html Content-Language: cs Content-Type: text/html; charset=ISO-8859-2V popisném souboru jsou popsány vąechny dostupné varianty jednoho dokumentu. Server pozná, ľe má pouľít pro dané URL popisný soubor variant podle toho, ľe existuje soubor se stejným jménem jako v URL a příponou danou konfigurací serveru (obvykle .var).
Při výběru mutace dokumentů se můľe stát, ľe ľádná z dostupných variant není pro klienta přijatelná. V tomto případě server můľe odpovědět chybovým kódem 406 (NOT ACCEPTABLE) a nabídnout dostupné varianty dokumentu:
HTTP/1.1 406 Not Acceptable Server: Apache/1.2b8 dev Vary: accept-language Connection: close Content-type: text/html <HTML><HEAD> <TITLE>406 Not Acceptable</TITLE> </HEAD><BODY> <H1>Not Acceptable</H1> An appropriate representation of the requested resource / could not be found on this server.<P> Available variants: <ul> <li><a href="index.html.czech">index.html.czech</a>, type text/html, language cs <li><a href="index.html.eng">index.html.eng</a>, type text/html, language en </ul> </BODY></HTML>Výběr varianty dokumentu na straně serveru byl sice definován aľ v protokolu http verze 1.1, ale je jiľ deląí dobu v mnoha serverech implementován a pouľíván. Přitom se začínají postupně objevovat nevýhody této koncepce. Předevąím popis přijatelných mutací dokumentu je u inteligentních prohlíľečů poměrně sloľitý a dlouhý, takľe by v plném tvaru podstatně prodluľoval kaľdý poľadavek. Naopak dokumenty obvykle nejsou dostupné ve vąech moľných mutacích, ale pouze v několika málo, například ve formátu text/html a application/pdf.. Proto klient posílá v hlavičkách Accept pouze omezenou podmnoľinu svých schopností a volba mutace na straně serveru nemůľe být díky tomu optimální. Proxy cache servery navíc musí ukládat dokumenty v různých variantách podle různých pouľitých preferencí klientů, přičemľ nemohou zjistit, zda různé preference nevedou na stejnou variantu dokumentu. Obvykle je počet dostupných mutací dokumentu podstatně menąí, neľ výčet mutací, které akceptuje klient. V protokolu http verze 1.1 je proto uvedena moľnost přenést výběr varianty dokumentů na stranu klienta. Konkrétní realizace je pak předmětem připravovaného standardu Transparent Content Negotiation.
GET /doc/VeryLongDocument.html HTTP/1.1 Range: 1000-8000,50000-Poľadovaná část je určena intervalem od počáteční po poslední poľadovanou slabiku dokumentu. Pokud není uvedena horní mez, je přenesen dokument aľ do konce. Pokud není uvedena dolní mez, je přenesen zadaný počet slabik od konce dokumentu. V jedné hlavičce můľe být uvedeno více intervalů, oddělených čárkami. Pokud klient poľaduje několik částí, zaąle je server ve tvaru zprávy o více částech ve formátu MIME. Kaľdá část navíc obsahuje hlavičku Content-Range, která identifikuje obsaľený interval:
Content-Type: multipart/x-byteranges; boundary=MARK --MARK Content-Type: text/html Content-Range: 1000-8000/327482 ... --MARK Content-Type: text/html Content-Range: 50000-327482/327482 ... --MARK